Kubernetes v1.33:流式 List 响应
随着基础设施的增长,管理 Kubernetes 集群的稳定性变得愈发重要。 在大规模集群的运维中,最具挑战性的操作之一就是处理获取大量数据集的 List 请求。 List 请求是一种常见的操作,却可能意外影响集群的稳定性。
今天,Kubernetes 社区非常高兴地宣布一项重大的架构改进:对 List 响应启用流式编码。
问题:大型资源导致的不必要内存消耗
当前的 API 响应编码器会将整个响应序列化为一个连续的内存块,并通过一次 ResponseWriter.Write 调用将数据发送给客户端。尽管 HTTP/2 能够将响应拆分为较小的帧进行传输, 但底层的 HTTP 服务器仍然会将完整的响应数据保存在一个单一缓冲区中。 即使这些帧被逐步传输到客户端,与这些帧关联的内存也无法被逐步释放。
随着集群规模的扩大,单个响应体可能非常庞大,可能达到几百兆字节。 在大规模环境下,当前的方式显得特别低效,因为它使得系统无法在传输过程中逐步释放内存。 想象一下,如果网络发生拥堵,那么大型响应体的内存块会持续占用数十秒甚至几分钟。 这一局限性导致 kube-apiserver 进程出现不必要的高内存占用,持续时间也很长。 如果多个大型 List 请求同时发生,累计的内存消耗可能迅速飙升,最终可能触发 OOM(内存溢出)事件,从而危及集群稳定性。
encoding/json 包在序列化时使用了 sync.Pool 来复用内存缓冲区。
这对于一致的工作负载来说是高效的,但在处理偶发性的大型 List 响应时却带来了新的挑战。
在处理这些大型响应时,内存池会迅速膨胀。而由于 sync.Pool 的设计特性,
这些膨胀后的缓冲区在使用后仍然会保留。后续的小型 List 请求继续使用这些大型内存分配,
导致垃圾回收无法生效,使得 kube-apiserver 在处理完大型响应后仍然保持较高的内存占用。
此外,Protocol Buffers(协议缓冲) 并不适合处理大型数据集。但它非常适合处理大型数据集中的单个消息。 这凸显出采用基于流式处理方式的必要性,这种方式可以逐步处理和传输大型集合,而不是一次性处理整个数据块。
一个通用的经验法则是:如果你处理的消息每个都大于一兆字节,那么可能需要考虑替代策略。
引自:https://protobuf.dev/programming-guides/techniques/
List 响应的流式编码器
流式编码机制是专门为 List 响应设计的,它利用了这类响应通用且定义良好的集合结构。 核心思想是聚焦于集合结构中的 Items 字段,此字段在大型响应中占用了大部分内存。 新的流式编码器不再将整个 Items 数组编码为一个连续的内存块,而是逐个处理并传输每个 Item, 从而在传输每个帧或数据块后可以逐步释放内存。逐项编码显著减少了 API 服务器所需的内存占用。
考虑到 Kubernetes 对象通常限制在 1.5 MiB(由 ETCD 限制),流式编码可使内存占用更加可预测和易于管理, 无论 List 响应中包含多少个对象。其结果是大幅提升了 API 服务器的稳定性,减少了内存峰值, 并改善了整体集群性能,尤其是在同时发生多个大型 List 操作的环境下更是如此。
为了确保完全向后兼容,流式编码器在启用前会严格验证 Go 结构体标签,确保与原始编码器在字节级别上保持一致。 标准编码机制仍然会处理除 Items 外的所有字段,从而保持输出格式的一致性。 这种方法无缝支持所有 Kubernetes 的 List 类型(从内置的 *List 对象到自定义资源的 UnstructuredList 对象) 客户端无需任何修改,也无需感知底层的编码方式是否已发生变化。
肉眼可见的性能提升
- 内存消耗降低: 当处理大型 list 请求,尤其是涉及大型资源时,API 服务器的内存占用大幅下降。
- 可扩展性提升: 允许 API 服务器处理更多并发请求和更大数据集,而不会耗尽内存。
- 稳定性增强: 降低 OOM 被杀和服务中断的风险。
- 资源利用率提升: 优化内存使用率,提高整体资源效率。
基准测试结果
为了验证效果,Kubernetes 引入了一个新的 list 基准测试,同时并发执行 10 个 list 请求,每个请求返回 1GB 数据。
此基准测试显示内存使用量下降了 20 倍,从 70–80GB 降低到了 3GB。
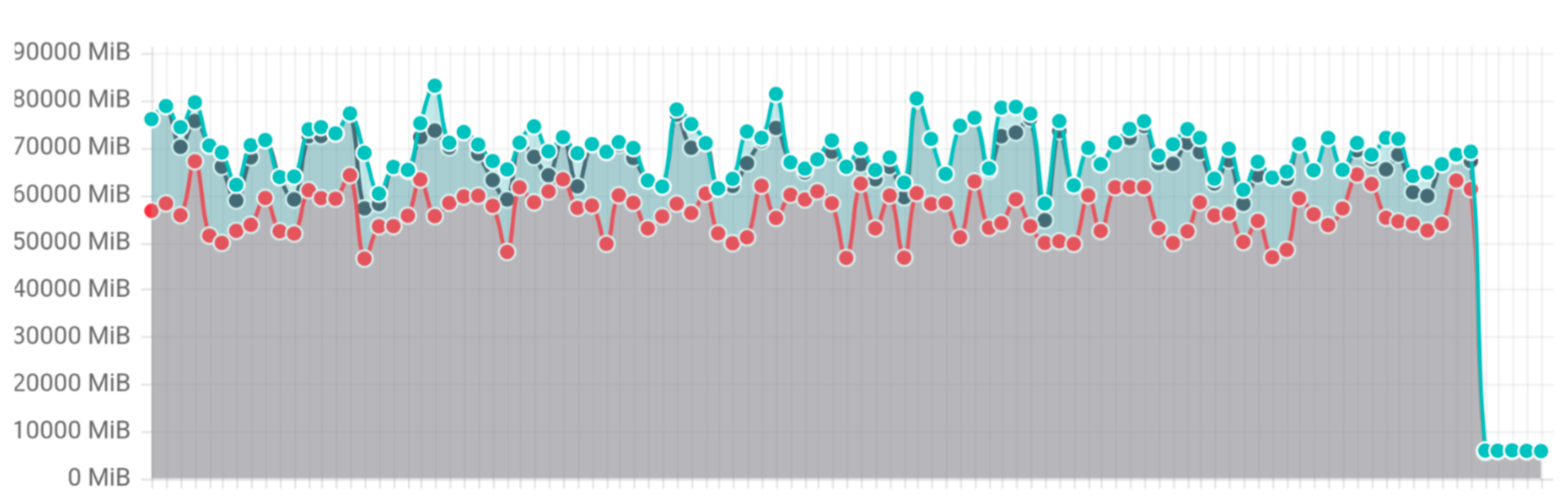
List 基准测试内存使用量